Using the JupyterLab Extension
This tutorial shows how to use the JupyterLab extension to clone and create research datasets using the graphical inteface of JupyterLab, and how to upload dataset to popular research data repositories.
If you haven not done so, install the full toolset.
Start JupyterLab
Star JupyterLab with the jupyter-fairly extension. This will start JupterLab in your browser.
Windows
You will use the Shell Terminal to start JupyterLab.
Important
For the following to work, you need Pyton in the PATH environment variable on Windows. If you are not sure that is the case. Open the Shell, and type python --version. You should see the version of Python on the screen. If you see otherwise, follow these steps to add Python to the PATH on Windows
On the shell type the following and press Enter:
jupyter lab
Linux / MacOS
From the terminal, run:
jupyter lab
JupyterLab should automatically start on you browser.

Part 1: Cloning Dastasets
Public research datasets can be cloned (copy and downloaded) directly to an empty directory, using the dataset’s URL or DOI. We will use this datset from 4TU.ResearchData as an example.
This are other datasets that you can try:
Using the JupyterLab interface, create a new directory called workshop. Notice that the content of your main directory would be different.
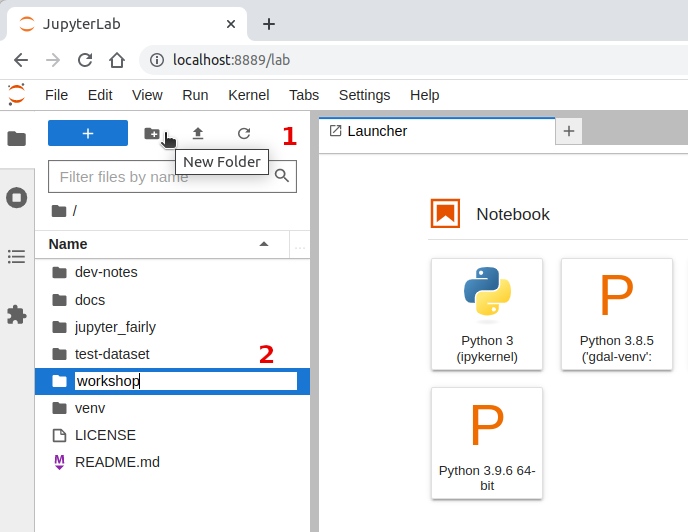
Inside the workshop directory, create a new directory called
cloneRight click on the left panel to open the context menu
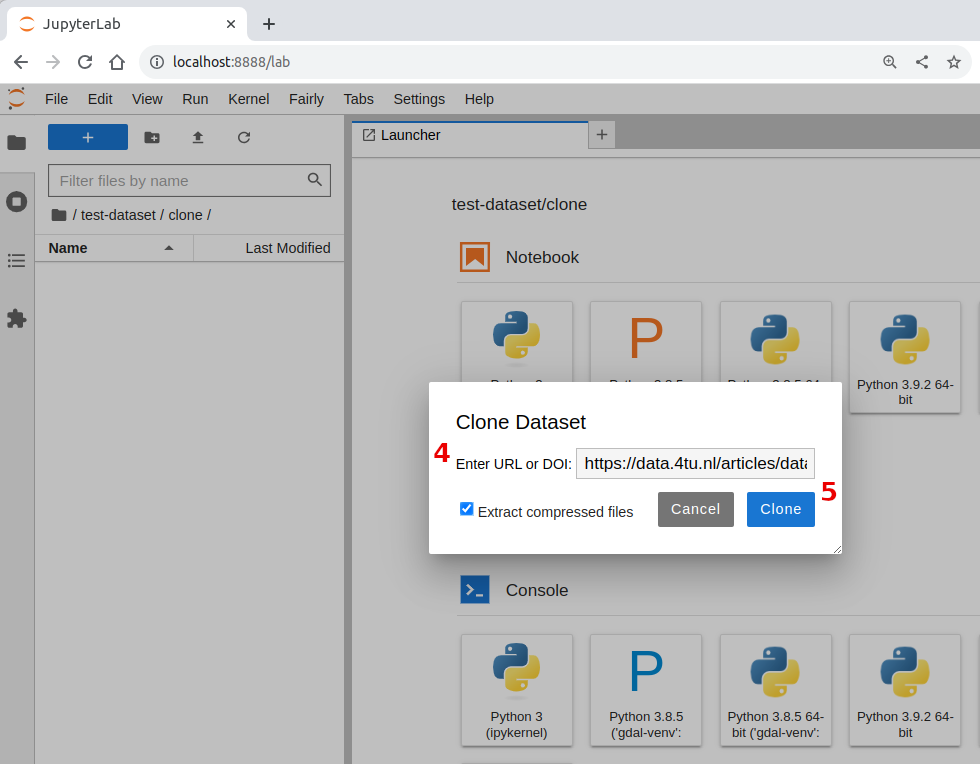
Click on Clone Dataset
Copy and paste the URL for the example dataset on the dialog window
Click Clone

A notification on the bottom-right corner will let you know when the cloning is complete, and you should see a list of files on JupyterLab. All the files, except for manifest.yaml are files that belong to the dataset in the research repository. The file manifest.yaml is automatically created by the Fairly Toolset, and it contains metadata from the research data repository, such as:
Authors
Keywords
License
DOI
Files in the dataset
etc.
Part 2: Create a Fairly Dataset
Here, we show you how can you create and prepare your own dataset using the JupyterLab extension of fairly.
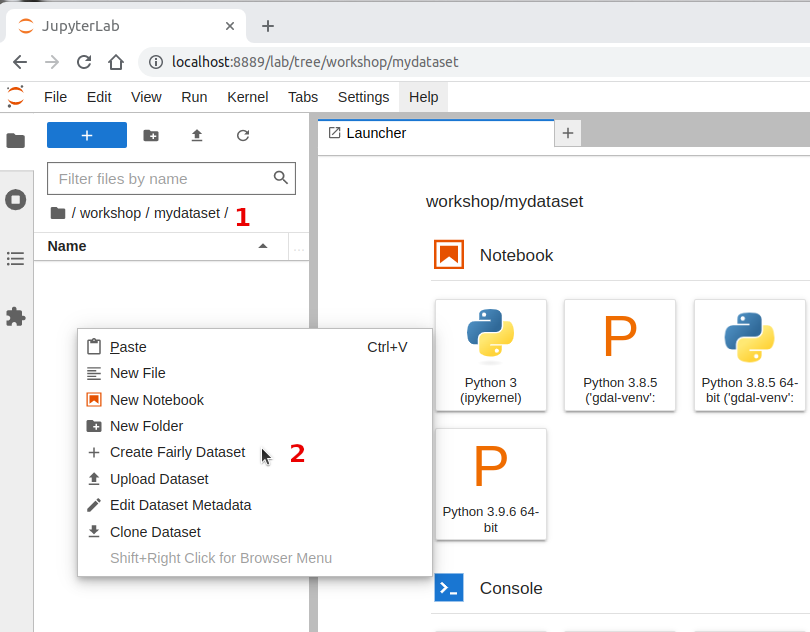
Create a new directory called
mydatasetinside the workshop directory.Inside
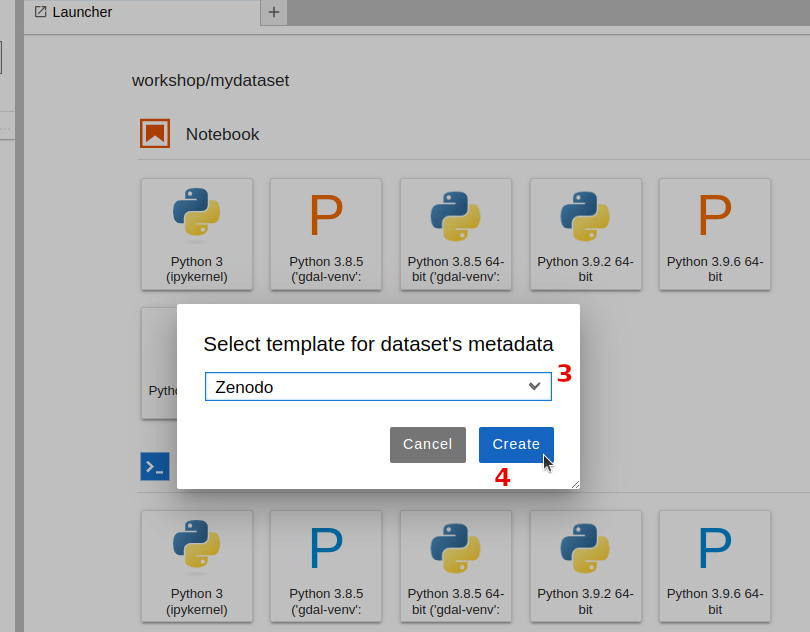
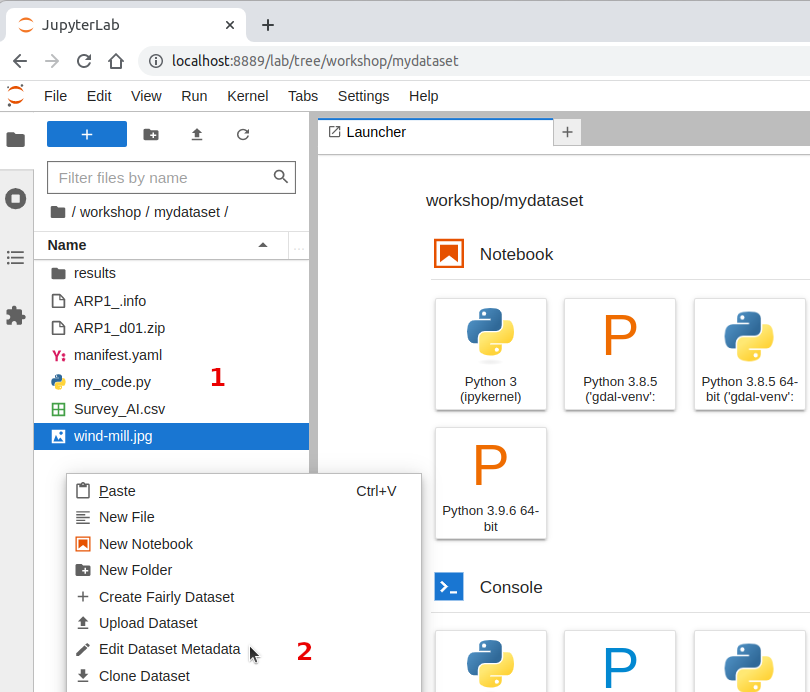
workshop/mydataset/. Open the context menu and click on Create Fairly DatasetSelect Zenodo as template from the drop-down list. Notice that there are templates for other data repositories.
Click Create. A
manifest.yamlfile will be add to the dummy-data directory. This file contains a list of fields that you can edit to add metadata to your dataset.
Include Files in your Dataset
Add some files to the mydataset directory. You can add files of your own, but be careful not to include anything that you want to keep confidential. Also consider the size of the files you will add, the larger the size the longer the upload will take. Also remember that for the current Zenodo API each file should be 100MB or smaller; this will change in the future.
If you do not want to use your own files, you can download and use the dummy-data
After you have added some file and/or folders to mydataset, JupyterLab should look something like this:
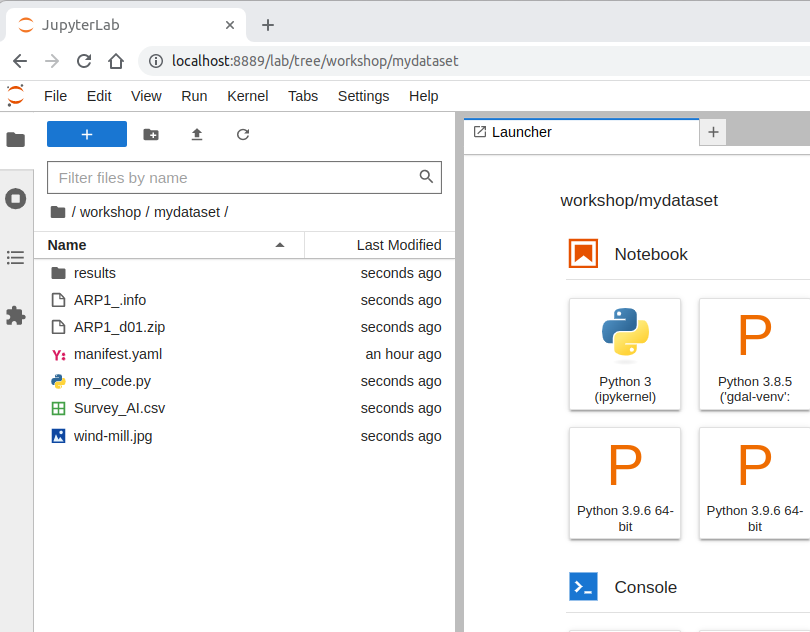
Editing the Manifest
The manifest.yaml file contains several sections to describe the medatadata of a dataset. Some of the sections and fiels are compulsory (they are required by the researh data repository), others are optional. In this example you started a fairly dataset using the template for the Zenodo repository, but you could also do so for 4TU.ResearchData.
However, if you are not sure which repository you will use to publish a dataset, use the Default template. This template contains the most common sections and fields for the repositories supported by the Fairly Toolset.
Tip
Independently of which template you use to start a dataset, the manifest.yaml file is interoperable between data repositories, with very few exceptions. This means that you can use the same manifest file for various data repositories. Different templates are provided only as a guide to indicate what metadata is more relevant for each data repository.
Open the
manifest.yamlfile using the context menu, or by doble-clicking on the file
Substitute the content of the
manifest.yamlwith the text below. Here, we use only a small set of fields that are possible for Zenodo.
metadata:
type: dataset
publication_date: '2023-08-31'
title: My Title
authors:
- fullname: Surname, FirstName
affiliation: Your institution
description: A dataset from the Fairly Toolset workshop
access_type: open
license: CC0-1.0
doi: ''
prereserve_doi:
keywords:
- fairly-toolset
- tutorial
- dummy data
notes: ''
related_identifiers: []
communities: []
grants: []
subjects: []
version: 1.0.0
language: eng
template: zenodo
files:
includes:
- ARP1_.info
- ARP1_d01.zip
- my_code.py
- Survey_AI.csv
- wind-mill.jpg
excludes: []
Edit the dataset metadata by typing the information you want to add. For example, you can change the title, authors, description, etc. Save the file when you are done.
Important
The
includesfield must list the files and directories (folders) you want to include as part of the dataset. Included files and directories will be uploaded to the the data repositoryThe
excludesfield can be used for explicitly indicating what files or directories you don’t want to be part of the dataset, for example, files that contain sensitive information. Excluded files and directories will never be uploaded to the data repository.Files and directories that are not listed in either
includesorexcludeswill be ignored by fairly.
Part 3: Upload Dataset to Repository
This part explains how to upload a dataset to an existing account in Zenodo. If you do not have an account yet, you can sign up in this webpage.
Create Personal Token
A personal token is a way in which data repositories identify a user. We need to register a personal token for creating datasets in the repository and uploading files to an specific account.
Sign in to Zenodo.
On the top-right corner click on drop-down arrow, then Applicaitons.
On the section Personal access tokens, click the New token button.
Enter a name for your token, for example:
workshopFor scopes, check all three boxes, and click Create
Copy the token (list of characters in red) to somewhere secure. You will only see the token once.
Under Scopes, check all three boxes once more. Then click Save
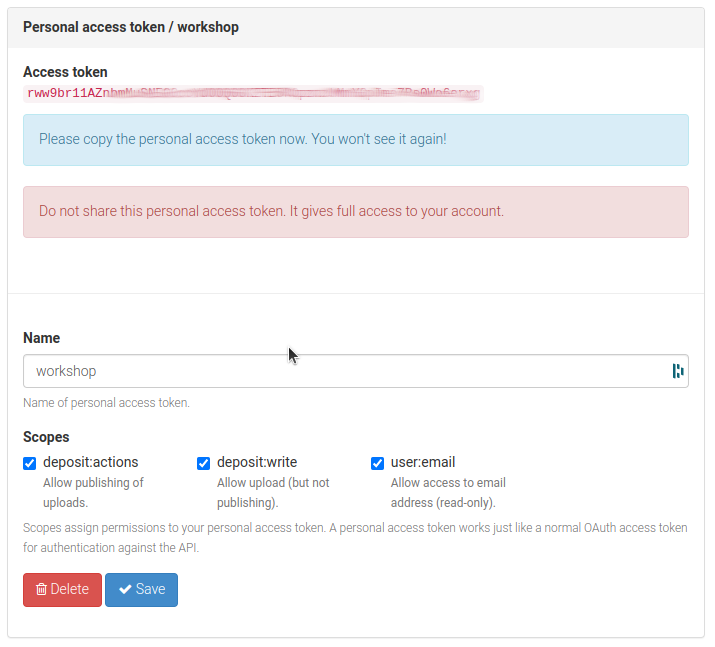
Register Personal Token
To register a personal token to the Fairly Toolset, do the following in JupyterLab:
Open the Fairly menu on the top menu bar, and click on Add Repository Token
Select Zenodo from the drop-down list.
Paste the token you copied from Zenodo in the previous step.
Click Add Token
Important
You can register tokens for other repositories supporte by fairly in the same way. Tokens added in this way are global, and will be used by by the JupyterLab extension, the Python package and the CLI.
Tokens are stored in a file called
config.jsonin your user home directory. This file is created automatically by fairly when you register a token. For Windows the file is located inC:\Users\<You-user-name>\.fairly\config.json, and for Linux/MacOS in~/.fairly/config.json.To update a token, simply register a new token with the same name. The old token will be replaced by the new one. To remove a token, simply repeate the process, but type a random character in the token field.
Warning
If you are using the Fairly Toolset in a shared computer, make sure that you remove your tokens from the JupterLab extension. Otherwise, other users of the computer will be able to use your token to create datasets in your account.
Note
Windows users might need to re-start JupyterLab for the tokens to work correctly when uploading datasets.
Upload Dataset
On the left panel, do right-click, and then click Upload Dataset
Select Zenodo from the dowp-down list, and click Continue
Confirm that you want to upload the dataset to Zenodo by ticking the checkbox.
Click OK. A notification on the bottom-right corner will let you know that the upload is in progress and when it is complete.
Go to your Zenodo account and click on Upload. The my dataset dataset should be there.
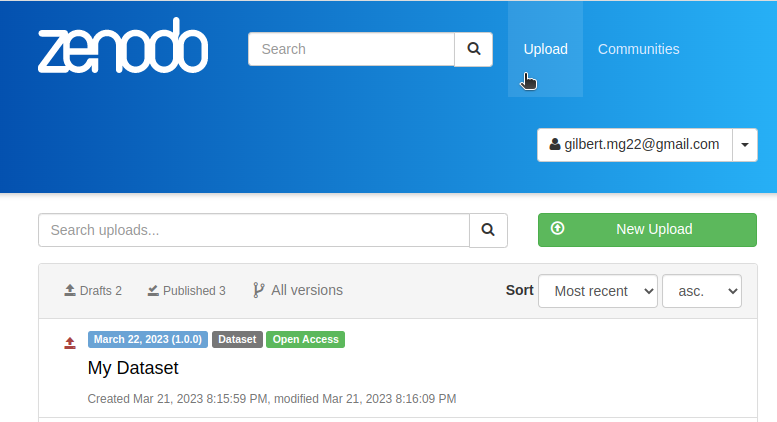
Explore the dataset and notice that all the files and metadata you added in JupyterLab has been automatically added to the new dataset. You should also notice that the dataset is not published, this is on purpose. This gives you the oportunity to review the dataset before deciding to publish if, and if necessary to make changes. In this way we also prevent users to publish dataset by mistake.
Note
If you try to upload the dataset again, you will get an error message. This is because the dataset already exists in Zenodo. You can see this reflected in the manifest.yaml file; the section remotes: is added to the file after succesfully uploading a dataset. It lists the names and ids of the repositories where the dataset has been uploaded.
In the future, we will add a feature to allow users to update and sync datasets between repositories.
Part 4: Pushing Changes to Data Repository
In the last part of this tutorial, we will show you how to push changes to a dataset that has already been uploaded to a data repository. For this, we will use the dataset we created in the previous part.
Attention
To be able to push updates to an existing dataset in a repository, you need to have write access to the dataset. For most of the repositories this requires you to be the owner of the dataset. Most data repositories prevent updates if a dataset is “published” (i.e. editing is limited to datasets that are not yet published).
You can make changes to the files in a local dataset as you would normally do. For example, you can add new files, edit existing files, or delete files. You can also edit the manifest.yaml file to update the metadata of the dataset.
If file inclusion or exclusion rules are defined using patterns (e.g. ‘*.txt’), then the extension automatically identifies added, removed, or modified files.
Otherwise, you need to explicitly indicate what needs to be included or excluded by updating the includes and excludes fields in the manifest.yaml file.
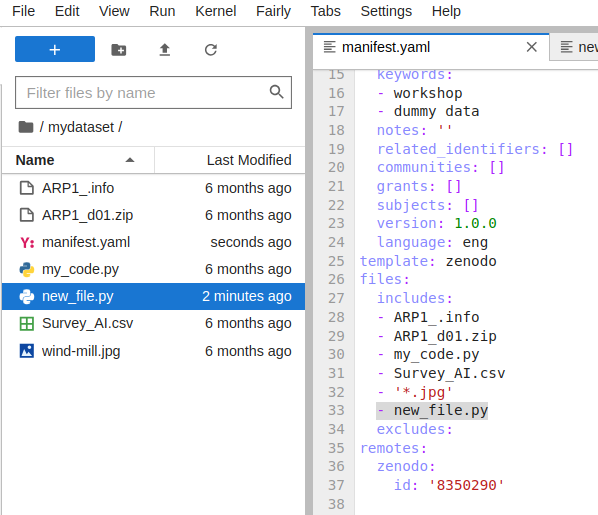
Once you have made and shaved the changes, you can do the following upload the changes to the data repository.
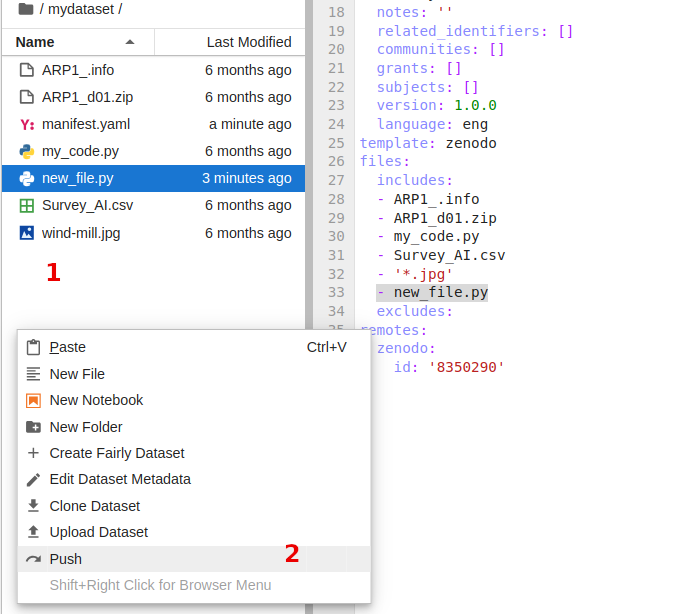
On the left panel, do right-click,
click Push option from the list,
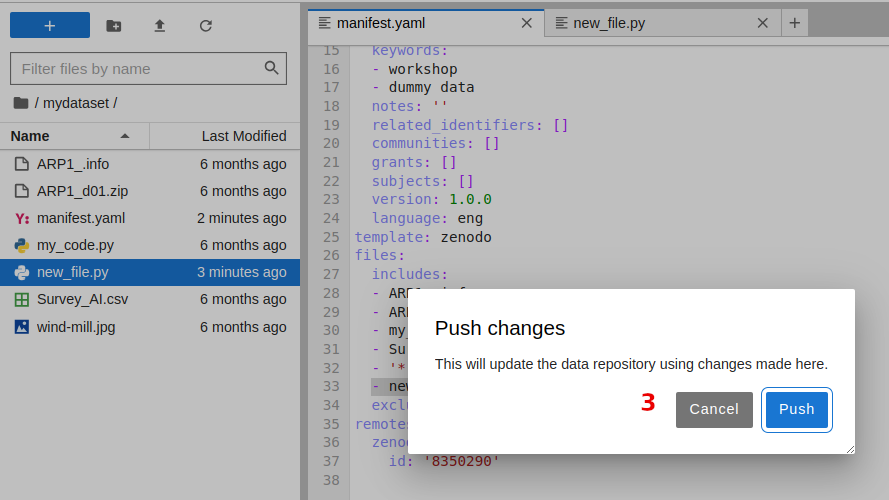
confirm that you want to push the changes and click Push button. A notification on the bottom-right corner will let you know that changes are in progress and when they are completed.
Tip
To push change to a dataset that you own, but you did not create using the Fairly Toolset, all you have to do is to clone it first, using the Clone Dataset option from the context menu. Then you will be able to make changes to the dataset and push them back to the data repository.